In times where both compute and predictive algorithms are both becoming commoditised, a core value that startups can add is in building the capability to quickly capture these datasets at scale, and as a result, deliver high performing ML products.

We have found that these approaches are especially valuable in cases where the data simply doesn’t exist historically, which is particularly evident in traditional industries and even more so in emerging markets.
An often overlooked component in building a defensible data stack is the process by which data is annotated. Annotation is the process of adding contextual information or labels to (in our startup’s case) images, which serve as training examples for algorithms to learn how to identify various features automatically. Aerobotics helps farmers with crop protection by building pest and disease monitoring solutions.
Insights are derived automatically from processing drone and satellite imagery, which can then be actioned through a range of web and mobile applications. Our proprietary dataset comprises of aerial multispectral images of trees labelled with specific pest/disease annotations, which is used to train networks capable of predicting the labels on previously unseen imagery.
Capturing this type of data at scale has been a challenge for us - mainly due to the complexity of the annotation process, where it is difficult to label the data due to the effort and skill needed in ground-truthing (to diagnose the issues with a tree). Lessons learned along the way have helped shape a data annotation workflow which we have scaled across various products.

In this piece, I will cover core considerations in developing a data annotation process through the lifecycle of a machine learning product - from collecting initial data to set up the annotation infrastructure, and finally optimising performance and running the process in production.
Acquiring the initial data
Once you have found a valuable proprietary dataset that you want to capture, a good starting point is in deciding how you can capture this as quickly and inexpensively as possible.
There are a few options, to begin with:
At Aerobotics, the way that we generated our own initial dataset was by building classical, rule-based models to annotate self-captured aerial imagery. Although this model wasn’t the smartest, it allowed us to provide enough initial value to our customer to start collecting data and proving product-market fit. These data were used to power our first production ML models.
Insource or outsource annotations?
After the raw data has been captured, it needs to be annotated before it is useful to use to train a machine learning algorithm. Depending on your dataset, annotations can be generated internally or outsourced to third-party service providers. These services are quickly becoming commercially available, particularly in generic computer vision applications like object detection/instance segmentation.
The decision on whether to annotate data internally or externally is driven by the following factors:
Complex data generally need specialised skills to label, as well as investment in educating and training annotators. Can you find external annotators that you won’t need to train?
Furthermore, is it worth your company having this expertise, and maintaining control in-house as long-term defensibility/flexibility as things change?
Again this is a function of the complexity of the annotation process. In our experience, we have found that the annotation tools (and resulting infrastructure) often require more engineering overhead than the ML itself. In taking on annotations internally, companies need to invest in the annotation product as a standalone product, from the UX in designing the tools to the content and education required to train annotators.
At Aerobotics, a large amount of our data requires domain expertise for labelling (in our case, trained agronomists), which has led to us building out an internal annotation capability. Given the cost and scarceness of this type of talent, we have found that it is important to find ways to scale our annotators’ knowledge over a product’s lifecycle so that our annotators don’t scale at the same rate as our data.
Building an annotation process which is more efficient in terms of agronomist time means that we aren’t purely limited by the number of agronomists that we can hire. This is achieved by embedding their knowledge in early versions of your models (generally in training model 1.0), annotation product and workflow design, and training documents.
Building annotation infrastructure
A basic annotation infrastructure (for a computer vision problem) consists of a front-end GUI, where annotators can load and label the data, and a back-end service to query the raw data and store the resulting annotations.
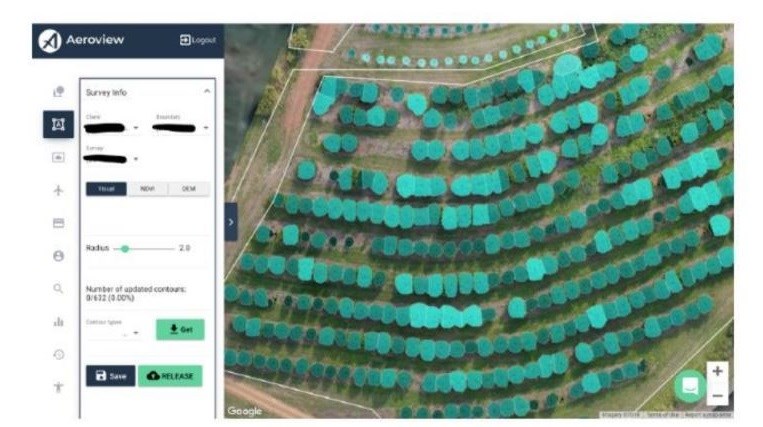
As with building any product, a good place to start is by putting together a list of requirements and understanding whether relevant off-the-shelf (and ideally open-source) tools are available as you build your annotation infrastructure. Since images are the main data we work with, at Aerobotics, we explored off-the-shelf options like LabelMe and Labelbox, which could easily be incorporated into your own products and allow you to quickly get a product up and running.
These tools are often quite generic, and as a result, can be limited if you have a niche use-case or dataset. We have generally found that the initial investment in building annotation products ourselves save the company from accumulating ‘annotation debt’.
Annotation debt refers to initially spending minimal time on annotation product development (typically through using third party products), to get a product out as quickly as possible - and as a result, slowing down the annotation process.
As your dataset scales, this can quickly become an operational problem which could have been avoided through better up-front product design. It is important to invest in formal and standardised training and education to help drive quality and consistency across different datasets and annotators.
Skipping this step can lead to ambiguity and, as a result, a lot of data that needs to be re-annotated later on, especially for data which requires a specific type of expertise or which has a tendency to include any subjectivity.
At Aerobotics, we have also built out a quality control process, which ensures that annotation outputs are validated by other people to drive better quality data. This process is achieved sequentially, after the initial annotation process where data is stochastically sent through for quality control (based on criteria such as the annotator experience and the data belonging to a new class, like a different crop type).
An alternative approach here could have multiple people simultaneously annotating the same image, and ensembling their responses together (which introduces a whole other problem). Given that the user is required to validate existing data, introducing bias is an important consideration (as in most of the steps in generating labelled data).
Finally, it is crucial to incorporate analytics to manage the annotation process in a data-driven manner, particularly given its operational nature.
At Aerobotics we have built trackers to continuously track annotation throughput and quality. This data is then used to manage the process, enabling us to measure how we are doing against targets which annotators are over/under-performing. The resulting knowledge is then used to help determine quality control criteria (e.g. it makes more sense to double-check a poor annotator’s work than a proficient annotator).
Increasing annotation efficiency
Now that you have built an annotation infrastructure, how do you enable annotators to output data more efficiently? In the early stages of annotating your models, it often makes sense to use more traditional approaches to serve as a base for your annotations.
This redefines annotators’ jobs to be more proofreading and correcting, rather than ‘writing’.
At Aerobotics we used more classical computer vision techniques (such as template matching, thresholding, and morphological operations), often through working with our domain experts, to label our initial data.
We have found that these approaches significantly reduce annotation time, and improve overall performance. Again, it is important to consider implicated biases in presenting an annotator with existing data, where a measured approach is required to avoid negatively impacting quality due to poor base models.
The annotation UX and interface is also more important than you think. Where it is of utmost importance to go through a full product development process is understanding and building for your users (annotators).
A well thought-out, simple interface goes a long way in driving consistent and high-quality annotations from your users. Generating synthetic data can also help maximise the output of a single annotation (as it would form an annotation for each corresponding generated dataset).
Options include simple data augmentation (noise, image transformations), or more complex approaches (using generative techniques to produce entirely new data). It may well be overwhelming to consider the complexity and investment required in spinning up your own annotation products and teams, but the ability to efficiently generate clean, annotated datasets at scale can be one of the core value-drivers of a business.
Annotating in production
In normal product development, the launch is the “end” of development. In annotation, as for the rest of machine learning, there is a continuous learning component in which constantly updates the model.
There are two types of annotation: the annotation of training data for an initial model launch and annotation for a model which is already in production. While the processes generate similar outputs, by nature they are quite different and require different thinking.
Annotating for your initial model launch is usually a large, once-off job to achieve baseline model performance. The data is at this point is usually quite one-dimensional (and as a result, easier to annotate consistently) due to the difficulties and costs involved in collecting raw data from wider distribution.
Annotating your model in production is a more continuous process with the goal of incrementally improving model performance (largely with better generalisation through getting exposed to a wider dataset in the wild).
At this point you likely already have customers and as a result, have more operational constraints on annotation quality and throughput.
Annotations in production can either be done in-the-loop (real time, before being seen by the customer) or offline. Another consideration is in onboarding new customers, and deciding if the data will be sufficiently similar to existing data (where you can use the same model) or if it is different enough to justify training a new model, and as a result, requires new data and annotations.
In-the-loop annotations are high frequency, smaller jobs which are generally completed when you have a small baseline dataset (and as a result, can impact model performance significantly with little additional data). This type of annotation is also necessary when the machine learning product is already embedded in your customer-facing product. Offline annotations are low frequency, batch jobs which aren’t immediately customer facing and can be completed asynchronously.
When to sunset the annotation processes?
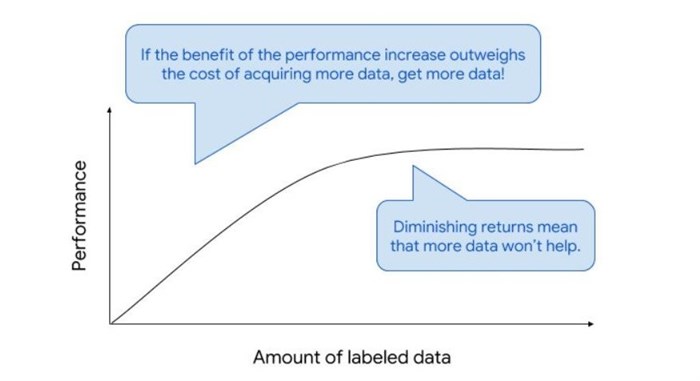
Your ML system should get smarter over time, and there should be a time when your annotators can focus on different problems that are not solved by your ML yet.
To this regard, it is important to frame your ML product well enough early - defining clear stopping criteria (which are generally a function of accuracy and cost) to avoid getting to a point of diminishing returns where additional effort and data doesn’t achieve justifiable performance improvements.
At this point it most likely makes sense to sunset the project and shifts your annotation focus onto new projects, expanding the general AI skill set in your company.









